Dataflow File: dataflow.yaml
The dataflow.yaml file defines the end-to-end composition DAG of the data-streaming application. The dataflows can perform a variety of operations, such as:
- routing with service chaining, split and merge
- shaping with transforms operators
- state processing with state operators
- window aggregates with window operators
and cover a board set of use cases.
The dataflow user-defined business logic can be applied inline or imported from packages. This document focuses on inline dataflows. The composition section defines dataflows imported from packages.
Service Composition
Services are core building blocks of a dataflow, where each service represents a flow that has one or more sources, one or more operators, and one or more destinations. Operators are processed in the order they are defined in the service definition. Each operator has an independent state machine.
Services that read from unrelated topics are processed in parallel, whereas services that read from a topic written by another service are processed in sequence.
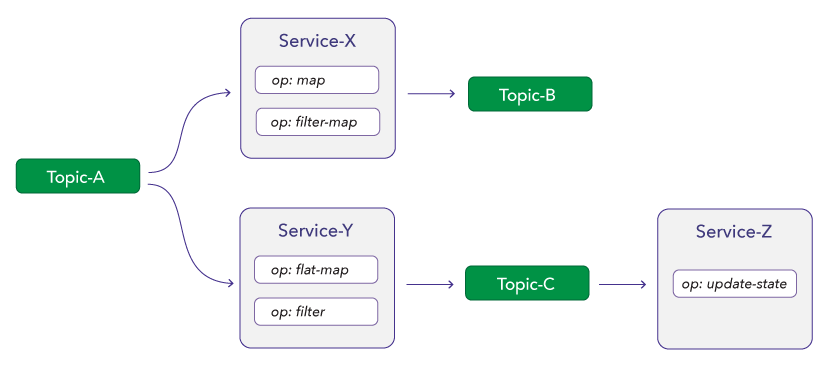
In this example, Service-X and Service-Y form a parallel chain, whereas Service-Y and Service-Z form a sequential chain.
The Services Section defines the different types of services the engine supports.
File: dataflow.yaml
The dataflow file is defined in YAML and has the following hierarchy:
apiVersion: <version>
meta:
<metadata-properties>
imports:
<import-properties>
config:
<config-properties>
types:
<types-properties>
topics:
<topics-properties>
services:
<service-properties>
dev:
<development-properties>
Where
- apiVersion - defines engine version of the dataflow file.
- meta - defines the name, version, and namespace of the dataflow.
- imports - defines the external packages
optional. - config - defines configurations applied to the entire dataflow file
optional. - types- defines the type definitions
optional. - topics - defines the topics used in the dataflow.
- services - defines the input, output, operators and states for each flow.
- dev - defines properties for developers
optional.
Let's go over each section in detail.
apiVersion
The apiVersion informs the engine about the runtime version it must use to execute a particular dataflow.
apiVersion: <version>
Where
- apiVersion - is the version number of the dataflow engine to use.
For example
apiVersion: 0.5.0
meta
Meta, short for metadata, holds the stateful dataflow properties, such as name & version.
meta:
name: <dataflow-name>
version: <dataflow-version>
namespace: <dataflow-namespace>
Where
- name - is the name of the dataflow.
- version - the version number of the dataflow (semver).
- namespace - the namespace this dataflow belongs to.
The tuple namespace:name becomes the WASM Component Model package name.
For example
meta:
name: my-dataflow
version: 0.1.0
namespace: my-org
imports
The imports section is used to import external packages into a dataflow. A package may define one or more types, functions, and states. A dataflow can import from as many packages as needed.
imports:
- pkg: <package-namespace>/<package-name>@<package-version>
types:
- name: <type-name>
functions:
- name: <function-name>
states:
- name: <state-name>
Where
- pkg - is the unique identifier of the package
- types - the list of types referenced by name.
- functions - the list of functions referenced by name.
- states - the list of states referenced by name.
For example
imports:
- pkg: my-dataflow/my-pkg@0.1.0
types:
- name: sentence
- name: word-count
functions:
- name: sentence-to-words
- name: augment-count
states:
- name: word-count-table
config
Config, short for configurations, defines the configuration parameters applied to the entire dataflow.
config:
converter:
<converter-properties>
consumer:
<consumer-properties>
producer:
<producer-properties>
Where
-
converter - define the default serialization/deserialization for reading and writing events. Supported formats are:
rawandjson. The converter configuration can be overwritten by the topic configuration. -
consumer - define the default consumer configuration. Supported properties are:
default_starting_offset- define the default starting offset for the consumer. The consumer can read frombeginningorendwith an offsetvalue. User0if you want to read the first or last item.
-
producer - define the default producer configuration. Supported properties are:
linger_ms- the time in milliseconds to wait for additional records to arrive before publishing a message batch.batch_size- the maximum size of a message batch.
Checkout batching for more details.
For example
config:
converter: json
consumer:
default_starting_offset:
value: 0
position: End
producer:
linger_ms: 0
batch_size: 1000000
All consumers start reading from the end of the data-stream and parse the records from json. All producers write their records to the data-stream in json.
Defaults
The config field is optional, and by default the system will read records from the end and decode records as raw.
topics
Dataflows use topics for internal and external communications. During the Dataflow initialization, the engine creates new topics or links to existing ones before it starts the services.
The topics have a definition section that defines their schema and a provisioning section inside the service.
The topic definition can have one or more topics:
topics:
<topic-name>:
schema:
key:
type: <type-name>
value:
type: <type-name>
converter:
<converter-type>
consumer:
<consumer-properties>
producer:
<producer-properties>
remote_cluster_profile: <optional-string>
Where
- topic-name - is the name of the topic.
- key - is the schema definition for the record key (optional).
- type - is the schema type for the key. The key only supports primitive types.
- value - is the schema definition for the record value
- type - is the schema type for the value.
- converter - is the converter to deserialize the key (optional - defaults to config).
- producer - is the producer configuration (optional - defaults to config).
- consumer - is the consumer configuration (optional - defaults to config).
- remote_cluster_profile - is the Fluvio profile that will be used to perform the connection. Useful to reach an external cluster.
For Example
topics:
cars:
schema:
value:
type: Car
converter: json
consumer:
default_starting_offset:
value: 0
position: End
car-events:
schema:
key:
type: CarLicense
value:
type: CarEvent
producer:
linger_ms: 0
batch_size: 1000000
The Key Handling section describes how to map topic keeps to functions.
types
Dataflows use types to define the schema of the objects in topics, states, and functions.
- Check out the Types section for the list of supported types.
services
Services define the dataflow composition and the business logic. Check out the Services section for details.
dev
The sdf section is used to test package without publishing them to the Hub.
To develop package from start:
- Create a local package
- Add
devsection to thedataflow.yamlfile to locate the local package. - Run the dataflow without the
--prodflag to load the local package instead of downloading them from the Hub. - Repeat the process until the package is ready for publishing.
- Then publish the package to the Hub.
Here is syntax for the dev section:
dev:
imports:
- pkg: <package-namespace>/<package-name>@<package-version>
path: <local path>
For Example
dev:
imports:
- pkg: example/sentence-pkg@0.1.0
path: ./packages/sentence
Dataflow Examples
- Checkout the github repo for dataflow examples.