Tumbling Window
SDF has a tumbling window that collects entries from the source for a fixed duration of the window before finally being sent to the sink topic. For more in-depth explanation about windows, read this. In this example, we will write a dataflow that aggregates the first digits of random numbers.
Prerequisites
This guide uses local Fluvio cluster. If you need to install it, please follow the instructions at here.
Dataflow
Overview
In this example, we will write a dataflow that aggregates the first digits of random numbers. For windows, we need to implement states to store data. To read more about states, the following page shows information about states.
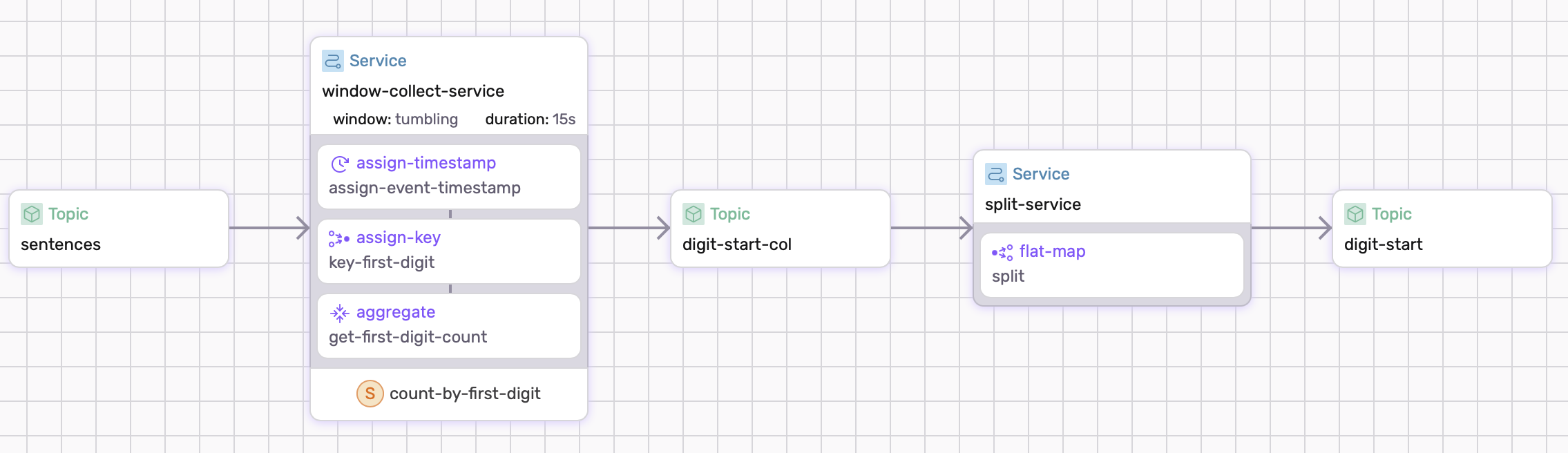
Define a state
The following is a simple state using a key-value pair.
states:
count-by-first-digit:
type: keyed-state
properties:
key:
type: string
value:
type: u32
Define a window
We will define a window with the following syntax
window:
tumbling:
(...)
watermark:
(...)
assign-timestamp:
(...)
partition:
assign-key:
(...)
transforms:
(...)
update-state:
(...)
flush:
(...)
Six components of a window
1. Add Window duration
tumbling:
duration: 15s
The above configuration sets the duration of the window to discrete 15 second blocks.
2. Assigning an idleness time and grace-period (optional)
watermark:
idleness: 60s
grace-period: 3s
watermark.idleness: 60s: This specifies that if there's no new data for 60 seconds, the window will be closed. This handles late-arriving eventswatermark.grace-period: 3s: This allows a 3 second grace period for out-of-order events. If an event arrives within this grace period after the window's end, it will still be included in the window's calculation. This prevents the dropping of slightly late events due to network delays or other factors.
3. Assigning a timestamp
assign-timestamp:
run: |
fn assign_event_timestamp(_str: String, time: i64) -> Result<i64> {
Ok(time)
}
The above code assigns a timestamp to each of the entries from the source. In other cases, if a timestamp is encoded in the data, the code could also instead use the encoded timestamp.
4. Assigning a partition key
assign-key:
run: |
fn key_first_digit(str: String) -> Result<String> {
if str.len() == 0 {
return Ok("empty".to_string());
}
Ok(str[0..1].to_string())
}
We need to make sure we have a mapping function that takes the string and maps it to a key. In this case, we are writing a dataflow that counts the number of occurance the first character appears in the window. Thus, the code just extracts the first digit as a key.
5. Update the state
update-state:
run: |
fn increment_digit_count(str: String) -> Result<()> {
count_by_first_digit().increment(1);
Ok(())
}
To update the state, we have to call the object created by the state listed above. The update-state will automatically apply the state instance of the parameter. For our case, we call the increment function. Each time a string appears, the function will update the mapped key's value. In this case, the first digit.
6. Flush the window
The final step is to flush the window. All the contents of the window gets popped and outputted into source.
flush:
run: |
fn get_first_digit_count() -> Result<String> {
let cc = count_by_first_digit().clone();
Ok(cc.into_iter().map(|(digit, count)|
format!("Numbers with {} occurred {} times,",digit,count)
).collect())
}
In the example above, we copy the state object and iterate through the keys. A output(in this case a string) is created every time the window flushes.
Splitting the collected data
The above example collects all the data into one object. This could be sufficient for formats like JSON where information is together in one object. However, breaking up the aggregated data into a topic is also possible with a simple flat-map as seen with the example service split-service.
transforms:
- operator: flat-map
run: |
fn split(input: String) -> Result<Vec<String>> {
let result: Vec<String> = input.split(',')
.map(|s| s.to_string())
.collect();
Ok(result)
}
Consuming the topic sentence-start will result in the individual entries neatly singled out in said topic.
Running the Example
Copy and paste following config and save it as dataflow.yaml. The first window-collect-service is defined from the outlined five parts above. The second service is reference in splitting the collected data.
# dataflow.yaml
apiVersion: 0.5.0
meta:
name: window-example
version: 0.1.0
namespace: examples
config:
converter: raw
topics:
sentences:
schema:
value:
type: string
digit-start-col:
schema:
value:
type: string
digit-start:
schema:
value:
type: string
services:
window-collect-service:
sources:
- type: topic
id: sentences
states:
count-by-first-digit:
type: keyed-state
properties:
key:
type: string
value:
type: u32
window:
tumbling:
duration: 15s
assign-timestamp:
run: |
fn assign_event_timestamp(_str: String, time: i64) -> Result<i64> {
Ok(time)
}
partition:
assign-key:
run: |
fn key_first_digit(str: String) -> Result<String> {
if str.len() == 0 {
return Ok("empty".to_string());
}
Ok(str[0..1].to_string())
}
update-state:
run: |
fn increment_digit_count(_str: String) -> Result<()> {
count_by_first_digit().increment(1);
Ok(())
}
flush:
run: |
fn get_first_digit_count() -> Result<String> {
let cc = count_by_first_digit().clone();
Ok(cc.into_iter().map(|(digit, count)|
format!("Numbers with {} occurred {} times,",digit,count)
).collect())
}
sinks:
- type: topic
id: digit-start-col
split-service:
sources:
- type: topic
id: digit-start-col
transforms:
- operator: flat-map
run: |
fn split(input: String) -> Result<Vec<String>> {
let result: Vec<String> = input.split(',')
.map(|s| s.to_string())
.filter(|s| !s.is_empty())
.collect();
Ok(result)
}
sinks:
- type: topic
id: digit-start
To run example:
$ sdf run
Produce random numbers with the following bash script.
while true; do
random=$RANDOM
echo "Random Number: $random"
echo "$random" | fluvio produce sentences
sleep 1
done
Consume topic sink topic for the digit-start-col in another topic.
$ fluvio consume digit-start-col -Bd
The output of the string is random, but should look something like this.
Numbers with 3 occurred 1 times,Numbers with 7 occurred 1 times,...
The output is a single entry in the sink topic.
Consuming the topic digit-start will result in something like the following
$ fluvio consume digit-start -Bd
Numbers with 8 occurred 1 times
Numbers with 9 occurred 1 times
Numbers with 2 occurred 6 times
Numbers with 1 occurred 3 times
Numbers with 3 occurred 1 times
Numbers with 5 occurred 1 times
In this case, every 15 seconds a new set of records are added to the topic.
Cleanup
Exit sdf terminal and clean-up. The --force flag removes the topics:
$ sdf clean --force
Conclusion
We just implemented tumbling windows. Windows can be applied to applications needing aggregated data over a specified time window.