Services
Services define the dataflow composition and the business logic. The composition is determined via sources and the sinks, and the business logic and the internal state by the transforms and the states.
Overview
Services can be molded to perform various operations, such as traffic routing, transformations, and window processing. We'll start with a brief overview of the architecture, followed by the service definition template, and conclude with several service definition examples for:
- Simple Transformations
- Data Routing with Merge and Split
- Parallel Processing with Partitions
- Window Processing
Service Architecture
Services are dataflow paths designed to perform one chain of operations in sequence. For example, the engine allows services to receive events from multiple sources and send their output to multiple sinks but restricts the transforms operations to execute sequentially.
Inside transforms, the engine sends the output of one operator to the input of the next operator, as defined in the dataflow file.
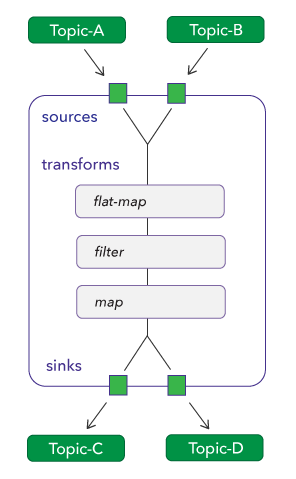
The only parallelism allowed is through partitions as described in the Partition section below.
Furthermore, window processing services are dedicated services that play a specific role in the dataflow implementation. They start the window keyword and perform pre-defined operations such as: assign-timestamp, partition, and flush. These services aim to create a state object that can be sent to a topic or referenced by other services.
Services Template Definition
Services are defined in the dataflow.yaml file and it has the following hierarchy:
services:
<service-name>:
sources:
-type: topic
id: <topic-name>
transforms:
- operator: <operator-props>
states:
<state-name>: <state-definition> | <state-reference>
transforms:
- operator: <operator-props>
window:
<window-props>
partition:
<partition-props>
sinks:
-type: topic
id: <topic-name>
transforms:
- operator: <operator-props>
Where:
- sources - has one or more references to topics, with an optional transformation. Checkout the merge section for examples on multiple sources.
- states - has
definitionsfor objects managed by the services, andreferencesto an external object. Checkout the states section for additional information. - transforms - define the operators to be applied to the data.
- window - defines the window processing parameters. Checkout window section below for additional information.
- partition - defines the parallelism of the transforms. Checkout partition section below for additional information.
- sinks - could be zero or multiples references to topics, with an optional transformation. Checkout the split section for examples on multiple destinations.
Services - Sample Use Cases
Services are like Lego; you can stitch them together in multiple ways to cover a high number of use cases. This section describes several use cases that should give you a better understanding on how to architect your own dataflow.
Simple Transformations
One of the simplest forms of services is a chain of operators that perform data transformations.
Inline Definition
In this example, we'll define a service that translates sentences into words and count the number of characters in each word.
services:
sentence-words:
sources:
- type: topic
id: sentence
transforms:
- operator: flat-map
run: |
fn sentence_to_words(sentence: String) -> Result<Vec<String>> {
Ok(sentence.split_whitespace().map(String::from).collect())
}
- operator: map
run: |
pub fn augment_count(word: String) -> Result<String> {
Ok(format!("{}({})", word, word.chars().count()))
}
sinks:
- type: topic
id: words
The service listens for events from a sentence topic, runs a flat-map operator sentence_to_words to split the sentence into words, and returns the result in an array of words. The engine passes the words to a map operator augment_count that counts the number of characters and appends the value to the word. After all transformations are completed, the result is sent to the words topic.
We defined the code inline for simplicity, but we could have placed it in a package and imported it from there.
Composition Definition
With composition, we build our code in packages, and import them into the dataflow file:
imports:
- pkg: example/sentence-pkg@0.1.0
functions:
- name: sentence-to-words
- name: augment-count
services:
sentence-words:
sources:
- type: topic
id: sentence
transforms:
- operator: flat-map
uses: sentence-to-words
- operator: map
uses: augment-count
sinks:
- type: topic
id: words
Packages allow you to write and test your code in your favorite editor instead of the yaml. During development, you can import the package locally, and in production, you can publish and import from InfinyOn Hub.
Check out the dataflow.yaml and sdf-package.yaml sections for additional information.
Data Routing with Merge and Split
It is often desirable to merge traffic from multiple topics or split the traffic into many topics. Some examples are splitting good and bad records,dividing user activity based on cohort or geo-location, or merging two datasets of similar properties. The dataflow can easily handle such scenarios.
Merge
For example, the following service definition merges traffic from the child and adult topics to the people topic:
services:
merge-service:
sources:
- type: topic
id: child
- type: topic
id: adult
sinks:
- type: topic
id: people
While sources and sinks allow for transformations, the formats in our example data match, so we are set.
Split
The following service definition splits the traffic from the people topic to the child and adult topics:
services:
split-service:
sources:
- type: topic
id: people
sinks:
- type: topic
id: child
transforms:
- operator: filter
run: |
fn is_child(person: Person) -> Result<bool> {
Ok(person.age < 18)
}
- type: topic
id: adult
transforms:
- operator: filter
run: |
fn is_adult(person: Person) -> Result<bool> {
Ok(person.age >= 18)
}
Generally, the engine sends the records to all matching topics. However, in this example, we'll use the filter operator to choose which record should be sent to the child and adult topics.
Check out the merge and split sections for additional information.
Parallel Processing with Partitions
Partitions give you the ability to divide the data in sets and process each data set in parallel.
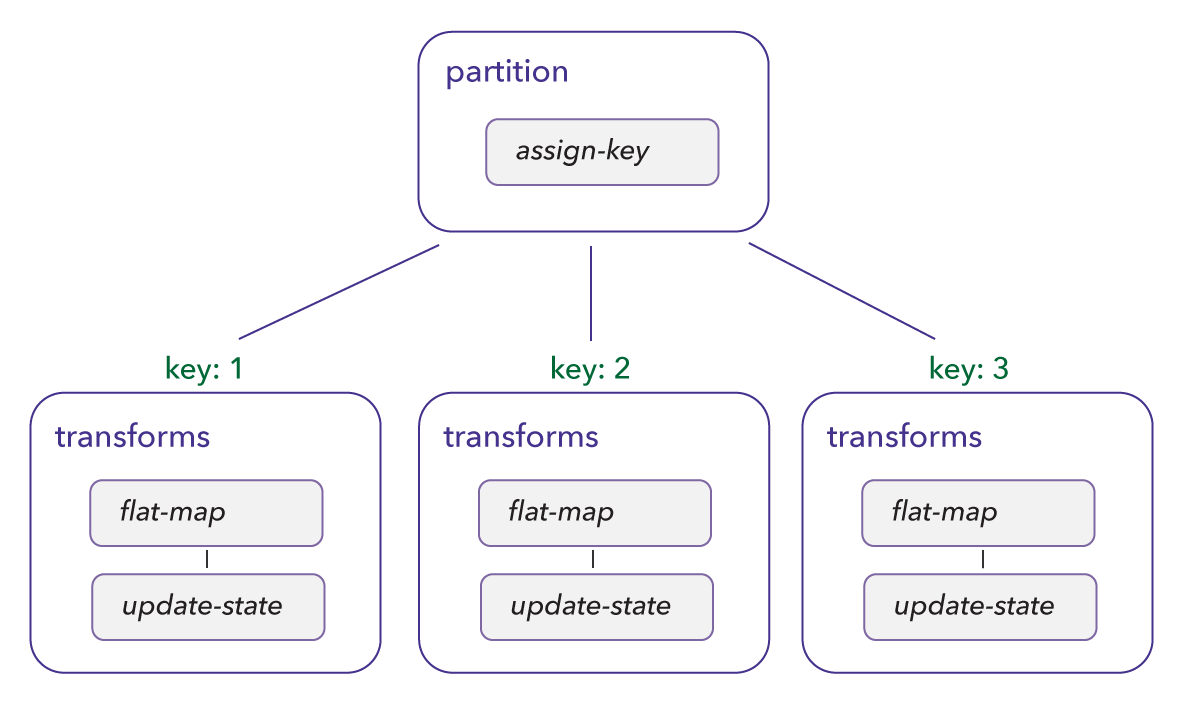
Say you have a stream of sentences where you want to count the occurrences of each word in all sentences. Partitioning helps to solve this problem by assigning a partition key to each word and incrementing each partition independently.
Partitions improve performance by processing records in parallel, and it also makes the custom code straightforward to write.
services:
transforms:
- operator: flat-map
run: |
fn split_sequence(sentence: String) -> Result<Vec<String>> {
Ok(sentence.split_whitespace().map(String::from).collect())
}
partition:
assign-key:
run: |
fn key_by_word(word: String) -> Result<String> {
Ok(word.to_lowercase().chars().filter(|c| c.is_alphanumeric()).collect())
}
update-state:
run: |
fn increment_word_count(_word: String) -> Result<()> {
let mut state = count_per_word();
state.count += 1;
state.update();
Ok(())
}
In this example, we use the flat-map operator to split the sentences into words and a partition section to group records by key. Inside partition, we use the assign-key operator to indicate the location of the key, and update-state operator to increment the count for each word.
Partition Requirements
- The
assign-keyandtransformsfields are mandatory. - The chain of operation in
transformsmust end withupdate-state.
Check out word-probe example in github for a working demo.
Window Processing
Window processing converts unbounded streams of records into bounded data sets suitable for counting, trend analysis, anomaly detection, data collection for dashboards and tables, materialized views, etc. Under the hood, Fluvio converts records into Apache Arrow format for fast and convenient access via third-party libraries such as Polars.
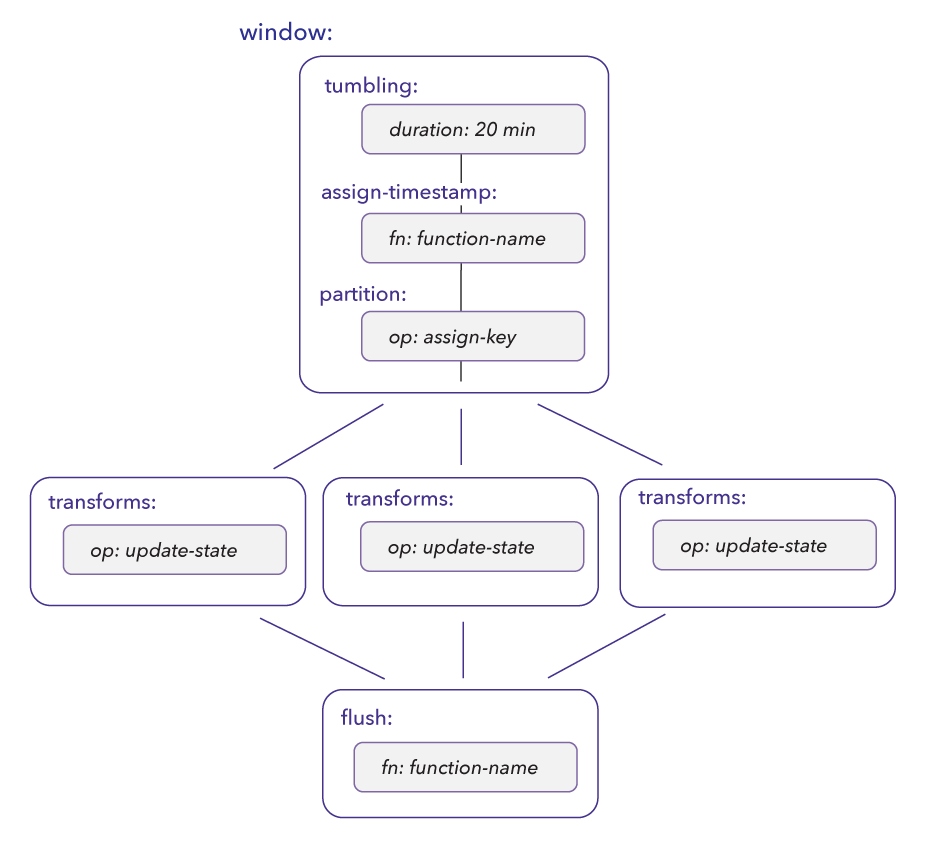
In this section we'll expand on the previous example by adding a window operator to count the top most used words in span of 20 seconds.
services:
window:
tumbling:
duration: 20s
assign-timestamp:
run: |
fn assign_event_timestamp(_value: String, event_time: i64) -> Result<i64> {
Ok(event_time)
}
partition:
assign-key:
run: |
fn assign_word_key(word: String) -> Result<String> {
Ok(word.to_lowercase().chars().filter(|c| c.is_alphanumeric()).collect())
}
update-state:
run: |
fn increment_word_count(word: String) -> Result<()> {
count_per_word().increment(1);
Ok(())
}
flush:
run: |
fn compute_most_used_words() -> Result<TopWords> {
let mut top3 = count_per_word().clone();
top3.sort_by(|a, b| a.value.cmp(&b.value));
top3.reverse();
top3.truncate(3);
Ok(top3.iter().map( | entry | WordCount { word: entry.key.clone(), count: entry.value }).collect())
}
In this example, we use the window operator to convert the stream of words into a tumbling windowed data set that flushes every 20 seconds.
Window Processing Requirements
- The
assign-timestampoperator to tell the engine which field to use for the timestamp. In this example, we use theevent_timefield from the record. For additional context, check out the timestamp operator section. - The
partitionoperator to group records by key (optional). - The
update-stateoperator to update the state on each record. - The
flushoperator returns the full data set for processing. The engine triggers theflush operationwhen the window closes, every 20 seconds.
Check out word-counter example in github for a working demo.